Основные определения, классификация распределенных систем
Основной причиной разработки систем, использующих базы данных, является стремление интегрировать все обрабатываемые в организации данные в единое Целое и обеспечить к ним контролируемый доступ. Хотя интеграция и предоставление контролируемого доступа могут способствовать централизации, последняя не является самоцелью. На практике создание компьютерных сетей приводит к децентрализации обработки данных. Децентрализованный подход отражает организационную структуру компании, логически состоящую из отдельных подразделений, отделов, проектных групп и тому подобного, которые физически распределены по разным офисам, отделениям, предприятиям или филиалам, причем каждая отдельная единица имеет дело с собственным набором обрабатываемых данных [7, 9].
Разработка распределенных баз данных позволяет сделать данные, поддерживаемые каждым из существующих подразделений организации, общедоступными, обеспечив при этом их сохранение именно в тех местах, где они чаще всего используются. Подобный подход расширяет возможности совместного использования информации, одновременно повышая эффективность доступа к ней.
Распределенные системы призваны разрешить проблему островов информации.
Базы данных иногда рассматривают как некие электронные острова, представляющие собой отдельные и, в общем случае, труднодоступные места, подобные удаленным друг от друга островам. Данное положение может являться следствием географической разобщенности, несовместимости используемой компьютерной архитектуры, несовместимости используемых коммутационных протоколов и т.д. Интеграция отдельных баз данных в одно логическое целое способна изменить подобное положение дел.
Распределенная база данных – набор логически связанных между собой разделяемых данных (и их описаний), которые физически распределены в некоторой компьютерной сети.
Распределенная СУБД – программный комплекс, предназначенный для управления распределенными базами данных и позволяющий сделать распределенность информации прозрачной для конечного пользователя.
Система управления распределенными базами дан-яйХ (СУРБД) состоит из единой логической базы дан-яых, разделенной на некоторое количество фрагментов.
Каждый фрагмент базы данных сохраняется на одном или нескольких компьютерах, которые соединены между собой линиями связи и каждый из которых работает под управлением отдельной СУБД. Любой из сайтов способен независимо обрабатывать запросы пользователей, требующие доступа к локально сохраняемым данным (что создает определенную степень локальной автономии), а также способен обрабатывать данные, сохраняемые на других компьютерах сети.
Пользователи взаимодействуют с распределенной базой данных через приложения. Приложения могут быть классифицированы как те, которые не требуют доступа к данным на других сайтах (локальные приложения), и те, которые требуют подобного доступа (глобальные приложения). В распределенной СУБД должно существовать хотя бы одно глобальное приложение, поэтому любая СУРБД должна иметь следующие особенности [7].
– Набор логически связанных разделяемых данных.
– Сохраняемые данные разбиты на некоторое количество фрагментов.
– Между фрагментами может быть организована репликация данных.
– Фрагменты и их реплики распределены по различным сайтам.
– Сайты связаны между собой сетевыми соединениями.
– Работа с данными на каждом сайте управляется СУБД.
– СУБД на каждом сайте способна поддерживать автономную работу локальных приложений.
– СУБД каждого сайта поддерживает хотя бы одно глобальное приложение.
Нет необходимости в том, чтобы на каждом из сайтов системы существовала своя собственная локальная база данных, что и показано на примере топологии СУРБД, представленной на рис. 5.1.
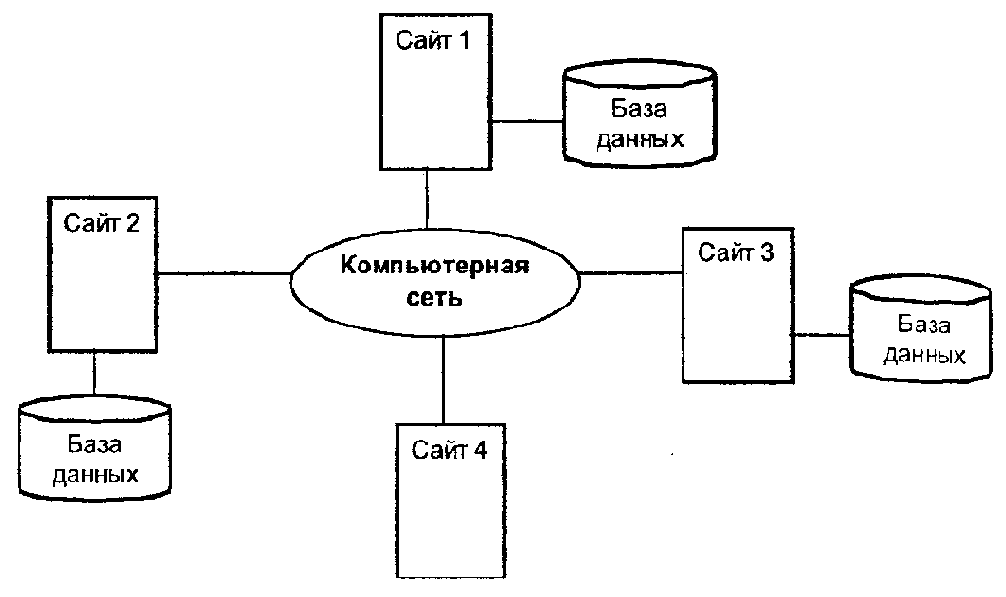
Рис. 5.1. Топология системы управления распределенной базой данных
Из определения СУРБД следует, что для конечного пользователя распределенность системы должна быть совершенно прозрачна (невидима). Другими словами, от пользователей должен быть полностью скрыт тот факт, что распределенная база данных состоит из нескольких фрагментов, которые могут размещаться на различных компьютерах и для которых, возможно, организована служба репликации данных.
Назначение обеспечения прозрачности состоит в том, чтобы распределенная система внешне вела себя точно так, как и централизованная. В некоторых случаях требование называют основным принципом построения распределенных СУБД [7]. Данный принцип требует предоставления конечному пользователю существенного диапазона функциональных возможностей, но, к сожалению, одновременно ставит перед программным обеспечением СУРБД множество дополнительных задач.
Очень важно понимать различия, существующие между распределенными СУБД и распределенной обработкой данных.
распределенная обработка – обработка с использованием централизованной базы данных, доступ к которой может осуществляться с различных компьютеров сети.
Ключевым моментом в определении распределенной базы данных является утверждение, что система работает с данными, физически распределенными в сети. Если данные хранятся централизованно, то даже в том случае, когда доступ к ним обеспечивается для любого пользователя в сети, данная система просто поддерживает распределенную обработку, но не может рассматриваться как распределенная СУБД.
Кроме того, следует четко понимать различия, существующие между распределенными и параллельными СУБД.
Параллельная СУБД – система управления базой Данных, функционирующая с использованием нескольких процессоров и устройств жестких дисков, что позволяет ей (если это возможно) распараллеливать выполнение некоторых операций с целью повышения °б1цей производительности обработки.
Появление параллельных СУБД было вызвано тем Фактом, что системы с одним процессором оказались неспособны удовлетворять растущие требования к мас- штабируемости, надежности и производительности обработки данных.
Эффективной и экономически обоснованной альтернативой однопроцессорным СУБД стали параллельные СУБД, функционирующие одновременно на нескольких процессорах. Применение параллельных СУБД позволяет объединить несколько маломощных машин для получения того же самого уровня производительности, что и в случае одной, но более мощной машины, с дополнительным выигрышем в масштабируемости и надежности системы, по сравнению с однопроцессорными СУБД.
Для предоставления нескольким процессорам совместного доступа к одной и той же базе данных параллельная СУБД должна обеспечивать управление совместным доступом к ресурсам. Какие именно ресурсы разделяются и как это разделение реализовано на практике, непосредственно влияет на показатели производительности и масштабируемости создаваемой системы, что, в свою очередь, определяет пригодность конкретной СУБД к условиям заданной вычислительной среды и требованиям приложений. Три основных типа архитектуры параллельных СУБД представлены на рис. 5.2. К ним относятся:
– системы с разделением памяти;
– системы с разделением дисков;
– системы без разделения.
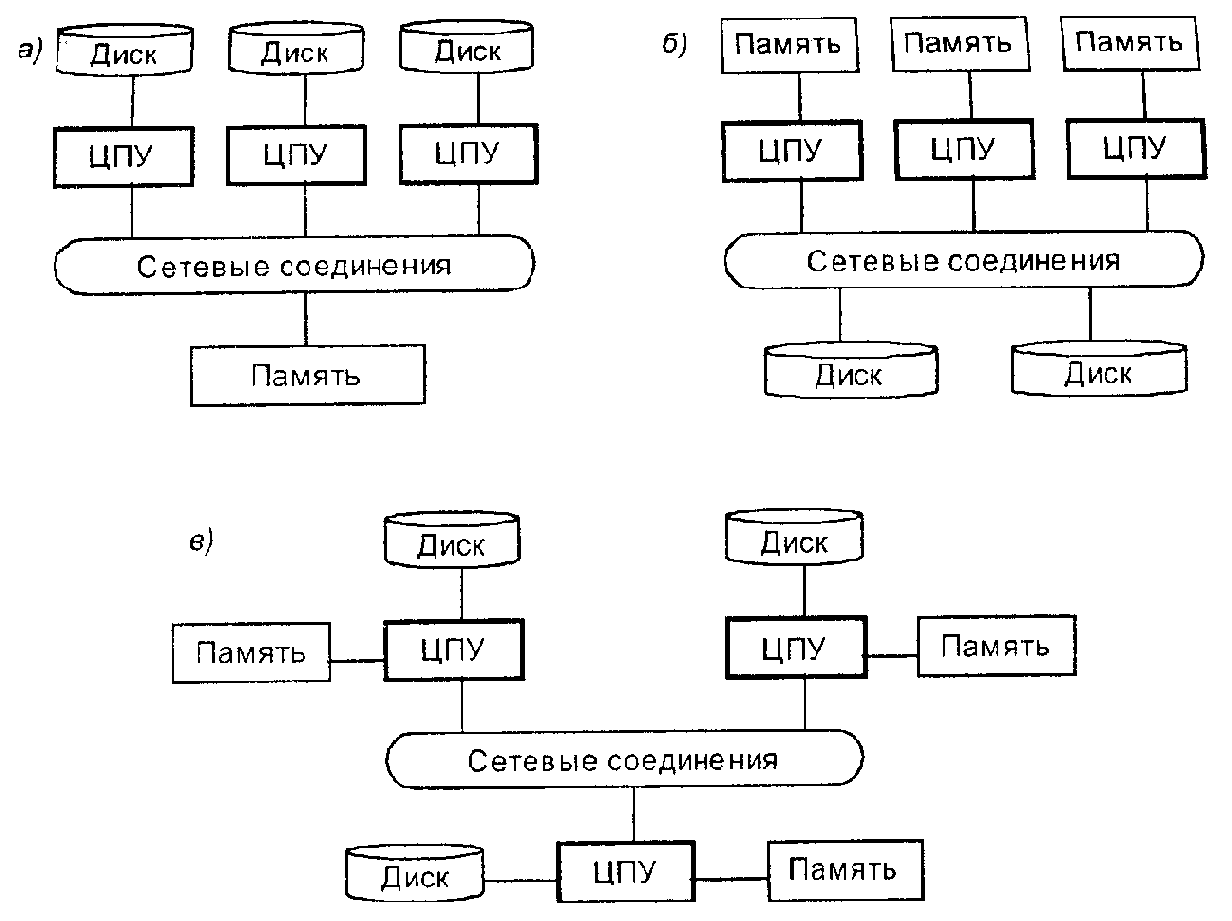
Рис. 5.2. Архитектура систем с параллельной обработкой: а) с разделением памяти; б) с разделением дисков; в) без разделения
Хотя схему без разделения в некоторых случаях относят к распределенным СУБД, в параллельных системах размещение данных диктуется исключительно соображениями производительности. Более того, узлы (сайты) распределенной СУБД обычно разделены географически, независимо администрируются и соединены между собой относительно медленными сетевыми соединениями, тогда как узлы параллельной СУБД чаще всего располагаются на одном и том же компьютере или в пределах одного и того же сайта [7].
Системы с разделением памяти состоят из тесно связанных между собой компонентов, в число которых входит несколько процессоров, разделяющих общую системную память. Иначе называемая симметричной многопроцессорной обработкой (СМП), эта архитектура в настоящее время приобрела большую популярность и применяется для самых разных вычислительных платформ, начиная от персональных рабочих станций, содержащих несколько параллельно работающих микропроцессоров, больших RISC-систем и вплоть до крупнейших мейнфреймов.
Данная архитектура обеспечивает быстрый доступ к данным для ограниченного числа процессоров, количество которых обычно не превосходит 64. В противном случае сетевые взаимодействия превращаются в узкое место,
ограничивающее производительность всей системы.
Системы, без разделения (эту архитектуру иначе называют массовой параллельной обработкой – ММП) используют схему, в которой каждый процессор, являющийся частью системы, имеет свою собственную оперативную и дисковую память. База данных распределена между всеми дисковыми устройствами, подключенным к отдельным, связанным с этой базой данных вычислительным подсистемам, в результате чего все данные прозрачно доступны пользователям каждой из этих подсистем. Данная архитектура обеспечивает более высокий уровень масштабируемости, чем системы с СМП, и позволяет легко организовать поддержку работы большого количества процессоров. Однако оптимальной производительности удается достичь только в том случае, если требуемые данные хранятся локально.
Системы с разделением дисков строятся из менее тесно связанных между собой компонентов. Они являются оптимальным вариантом для приложений, которые унаследовали высокую централизацию обработки и должны обеспечивать самые высокие показатели доступности и производительности. Каждый из процессоров имеет непосредственный доступ ко всем совместно используемым дисковым устройствам, но обладает собственной оперативной памятью. Как и в случае архитектуры без разделения, архитектура с разделением дисков исключает узкие места, связанные с совместно используемой памятью. Однако, в отличие от архитектуры без разделения, данная архитектура исключает упомянутые узкие места без внесения дополнительной нагрузки, связанной с физическим распределением данных по отдельным устройствам. Разделяемые дисковые системы в некоторых случаях называют кластерами.
Параллельные технологии обычно используются в случае исключительно больших баз данных, размеры которых могут достигать нескольких терабайт (1012 байт), или в системах, которые должны поддерживать выполнение тысяч транзакций в секунду.
Подобные системы нуждаются в доступе к большому объему данных и должны обеспечивать приемлемое время реакции на запрос. Параллельные СУБД могут использовать различные вспомогательные технологии, позволяющие повысить производительность обработки сложных запросов за счет применения методов распараллеливания операций сканирования, соединения и сортировки, что позволяет нескольким процессорным узлам автоматически распределять между собой текущую нагрузку [7].
Распределенные СУБД можно классифицировать как гомогенные и гетерогенные
[7].
В гомогенных системах все сайты используют один и тот же тип СУБД.
В гетерогенных системах на сайтах могут функционировать различные типы СУБД, использующие разные модели данных, т.е. гетерогенная система может включать сайты с реляционными, сетевыми, иерархическими или объектно-ориентированными СУБД.
Гомогенные системы значительно проще проектировать и сопровождать. Кроме того, подобный подход позволяет поэтапно наращивать размеры системы, последовательно добавляя новые сайты к уже существующей распределенной системе. Дополнительно появляется возможность повышать производительность системы за счет организации на различных сайтах параллельной обработки информации.
Гетерогенные системы обычно возникают в тех случаях, когда независимые сайты, уже эксплуатирующие свои собственные системы с базами данных, интегрируются во вновь создаваемую распределенную систему. В гетерогенных системах для организации взаимодействия между различными типами СУБД потребуется организовать трансляцию передаваемых сообщений. Для обеспечения прозрачности в отношении типа используемой СУБД пользователи каждого из сайтов должны иметь возможность вводить интересующие их запросы на языке той СУБД, которая используется на данном сайте. Система должна взять на себя локализацию требуемых данных и выполнение трансляции», передаваемых сообщений. В общем случае данные могут быть затребованы с другого сайта, который характеризуется такими особенностями, как:
– иной тип используемого оборудования;• иной тип используемой СУБД;
– иной тип применяемых оборудования и СУБД,
Если используется иной тип оборудования, однако да сайте установлен тот же самый тип СУБД, методы выполнения трансляции вполне очевидны и включают замену кодов и изменение длины слова. Если типы используемых на сайтах СУБД различны, процедура трансляции усложняется тем, что необходимо отображать структуры данных одной модели в соответствующие структуры данных другой модели. Например, отношения в реляционной модели данных должны быть преобразованы в записи и наборы, типичные для сетевой модели данных. Кроме того, потребуется транслировать текст запросов с одного используемого языка на другой (например, запросы с SQL-оператором STLECT потребуется преобразовать в запросы с операторами FIND и GET языка манипулирования данными сетевой СУБД). Если отличаются и тип используемого оборудования, и тип программного обеспечения, потребуется выполнять оба вида трансляции. Все изложенное выше чрезвычайно усложняет обработку данных в гетерогенных СУБД.
Дополнительные сложности возникают при попытках выработки единой концептуальной схемы, создаваемой путем интеграции независимых локальных концептуальных схем.
Типичное решение, применяемое в некоторых реляционных системах, состоит в том, что отдельные части гетерогенных распределенных систем должны использовать шлюзы, предназначенные для преобразования языка и модели данных каждого из используемых типов СУБД в язык и модель данных реляционной системы. Однако подходу с использованием шлюзов свойственны некоторые серьезные ограничения.
Во-первых, шлюзы не позволяют организовать систему управления транзакциями даже для отдельных пар систем. Другими словами, шлюз между двумя системами представляет собой не более чем транслятор запросов. Например, шлюзы не позволяют системе координировать управление параллельностью и процедурами восстановления транзакций, включающих обновление данных в обеих базах.
Во-вторых, использование шлюзов призвано лишь решить задачу трансляции запросов с языка одной СУБД на язык другой СУБД.
Поэтому они не позволяют справиться с проблемами, вызванными неоднородностью структур и представлением данных в различных схемах.
В настоящее время организована рабочая группа (Specification Working Group – 8ЛУО) для подготовки спецификаций, регламентирующих инфраструктуру среды базы данных, включающую следующие элементы [7].
1. Унифицированный и достаточно мощный интерфейс языка SQL (SQL API), позволяющий создавать клиентские приложения таким образом, чтобы они не были привязаны к конкретному типу используемой СУБД.
2. Унифицированный протокол доступа к базе данных, позволяющий СУБД одного типа непосредственно взаимодействовать с СУБД другого типа, без необходимости использования какого-либо шлюза.
3. Унифицированный сетевой протокол, позволяющий осуществлять взаимодействие СУБД различного типа.
Самой важной задачей этой группы следует считать отыскание способа, позволяющего в одной транзакции выполнять обработку данных, содержащихся в нескольких базах, управляемых СУБД различных типов, причем без необходимости использования каких-либо шлюзов.
Одной из разновидностей распределенных СУБД, являются мультибазовые системы.
Мулътибазовая система – распределенная система управления базами данных, в которой управление каждым из сайтов осуществляется совершенно автономно.
В последние годы заметно возрос интерес к мульти-базовым СУБД, в которых предпринимается попытка интеграции таких распределенных систем баз данных, в которых весь контроль над отдельными локальными системами целиком и полностью осуществляется их операторами. Одним из следствий полной автономии сайтов является отсутствие необходимости внесения каких-либо изменений в локальные СУБД. Следовательно, мультибазовые СУБД требуют создания поверх существующих локальных систем дополнительного уровня программного обеспечения, предназначенного для предоставления необходимой функциональности.
Мультибазовые системы позволяют конечным пользователям разных сайтов получать доступ и совместно использовать данные без необходимости физической интеграции существующих баз данных.
Они обеспечивают пользователям возможность управлять базами данных их собственных сайтов без какого-либо централизованного контроля, который обязательно присутствует в обычных типах СУРБД. Администратор локальной базы данных может разрешить доступ к определенной части своей базы данных посредством создания схемы, экспорта, определяющей, к каким элементам локальной базы данных смогут получать Доступ внешние пользователи. Различают нефедеральные (не имеющие локальных пользователей) и федеральные
мультибазовые системы. Федеральная система представляет собой некоторый гибрид распределенной и централизованной систем, поскольку она выглядят как распределенная система для удаленных пользователей и как централизованная система – для локальных.
Говоря простыми словами, мультибазовая СУБД является такой СУБД, которая прозрачным образом располагается поверх существующих баз данных и файловых систем, предоставляя их своим пользователям как некоторую единую базу данных. Мультибазовая СУБД поддерживает глобальную схему, на основании которой пользователи могут строить запросы и модифицировать данные. Мультибазовая СУБД работает только с глобальной схемой, тогда как локальные СУБД собственными силами обеспечивают поддержку данных всех их пользователей. Глобальная схема создается посредством интеграции схем локальных баз данных. Программное обеспечение мультибазовой СУБД предварительно транслирует глобальные запросы и превращает их в запросы и операторы модификации данных соответствующих локальных СУБД. Затем полученные после выполнения локальных запросов результаты сливаются в единый глобальный результат, предоставляемый пользователю. Кроме того, мультибазовая СУБД осуществляет контроль за выполнением фиксации или отката отдельных операций глобальных транзакций локальных СУБД, а также обеспечивает сохранение целостности данных в каждой из локальных баз данных. Программы мультибазовой СУБД управляют различными шлюзами, с помощью которых они контролируют работу локальных СУБД.
